Common Crawl
This is a hand-in for the Common Crawl assignment of the Big
Data course at the Radboud University, Nijmegen.
Back to the blog index.
Introduction
In our previous big data adventures, we have seen how to apply big data techniques in cryptography and functional programming. Neither of these topics required a big data solution. In this final assignment, we take on a task which cannot be solved by conventional methods. We use the data of the Common Crawl, a full index of the public internet.
The bible is a book with millions of readers world-wide. It consists of several books that have been written over centuries, approximately from 1500 B.C.E. to the first centuries C.E. Due to complicated redaction events, it contains duplicate texts and highly similar stories. Moreover, because of the importance writers gave to the already existing texts, it is full of cross-references. For example, the author of the Gospel according to Matthew attempts to give the events he narrates more value by aligning them to prophesies in Isaiah. Compare Matthew 1:22-23 to Isaiah 7:14:
All this took place to fulfill what the Lord had said through the prophet: “The virgin will conceive and give birth to a son, and they will call him Immanuel” (which means “God with us”). — Matthew 1:22-23 NIV
Therefore the Lord himself will give you a sign: The virgin will conceive and give birth to a son, and will call him Immanuel. — Isaiah 7:14 NIV
Many bible translations offer more or less extensive lists of cross-references as foot- or margin notes. There is at least one public database of cross-references, provided by OpenBible.info. All these collections ultimately rely on hard work by scholars. On the internet many people discuss bible texts. We intend to find cross-references by finding co-mentioned bible references in the Common Crawl.
Not only can we hope to find some cross-references that have been found up by careful laymen readers but have not been picked up in academia. We also hope to find more obscure cross-references, that is, references on a higher level than the textual level. An example of this may be Lamentations 1:12 with Ezekiel 5:14:
“Is it nothing to you, all you who pass by? Look around and see. Is any suffering like my suffering that was inflicted on me, that the Lord brought on me in the day of his fierce anger? — Lamentations 1:12 NIV
“I will make you a ruin and a reproach among the nations around you, in the sight of all who pass by.” — Ezekiel 5:14 NIV
The bible is full of pairs of passages that could be read together in some understanding, but are not related enough to end up in a cross-reference database. However, people may write about them, for example in blogs.
Reading the Common Crawl
To experiment with the Common Crawl data, I downloaded a single segment, containing data from Hermeneutics SE. This allowed me to work on a small, dense data-set (thus providing plenty of data to analyse in a small enough data-set to develop the miner logic efficiently).
Parsing bible references
For simplicity, I ‘round’ references to their chapter, thus removing the verse
part. Hence, the reference Mt 1:22-23 will be parsed as Matthew 1.
There are multiple standards for abbreviating bible books. Logos software provides a list of common abbreviations. The reference parser accepts any of these abbreviations followed by a number. It then gives back the full name of the book and the chapter. This is done using a simple regular expression and a table of abbreviations:
def findBook(abbreviation : String) : String = {
val books = List(
List("genesis", "gen", "ge", "gn"),
List("exodus", "exo", "ex", "exod"),
// ...
)
val bookname = abbreviation.toLowerCase()
for (alts <- books; alt <- alts) if (bookname.equals(alt)) return alts(0)
"ERR"
}
def findReferences(content : String) : List[(String, Int)] = {
val chap_rgx = raw"\b(?i)(Genesis|Gen|Ge|Gn|Exodus|...)\s+({1,3}+)\b".r
val matches = (for (m <- chap_rgx.findAllMatchIn(content)) yield (m.group(1), m.group(2))).toList
var results = List[(String,Int)]()
for (m <- matches) results = (findBook(m._1), m._2.toInt) :: results
return results.distinct
}
Rewriting to a map-reduce task
In the end, we want to have data of the type [(RefPair, Int)], where
RefPair is a pair of references to bible passages and the Int element
indicates the number of times the pair occurs in the corpus. This is similar to
a word-count task, although we are working with RefPairs rather than words.
The bible has little over 1,000 chapters, so we will find at most 500,000 pairs
(which passage is the first element of the pair is irrelevant). If we reserve
about 40 bytes per (RefPair, Int) tuple, we need 20MB for the whole
result set. This is convenient, as it can be analysed on a single machine.
Hence, we only need the cluster for the initial indexing.
In pseudo-code, our map-reduce task looks like this:
function map(content) :
references <- findReferences(content)
for (refA <- 0 until references.length)
for (refB <- refA + 1 until references.length)
emit ((references[refA], references[refB]), 1)
function reduce(refPair, counts) :
emit (refPair, sum(counts))
Rating pairs
Not all pairs of references are equal. Intuitively, when two references occur
on short distance from each other, we can expect them to be more closely
related. Hence, rather than emitting 1 in the mapper for every pair, we
should determine the minimum distance between the two references on the page
(references may be repeated, of course).
To this end, we adapt findReferences to return a
List[(String, Int, List(Int)], where the third element of the tuple is a list
of occurrences of the reference. The mapper should then use these lists to
determine the shortest distance between two occurrences (in O(max(m,n)) for
references with m and n occurrences).
We need to normalise these values to account for different writing styles and text types. For instance, lexicons will have high density but many of the pairs we may find there are largely irrelevant. For a page with c characters of text and r references, we may consider references with a distance in O(c/r) ‘relevant’. Hence, for a pair with distance d we emit c / d / r.
This is still not ideal. We should also account for the place in the document.
If we look at Hermeneutics Stack Exchange, we will find many close
reference pairs in the sidebar, because it lists titles. We even find pairs
from different titles, while the questions they link to may not be related. One
way to account for this would be to use the DOM graph to create a different
distance measure. References in question bodies will be closely related in the
DOM graph, as they are just from different <p> tags in the same container.
References in the sidebar will be further removed, because they are <a> tags
wrapped in <li>. At this moment, DOM distance is not implemented and we
assume the artefacts to be insignificant over the whole corpus.
Efficiency and legitimacy
The regular expression used for parsing bible references is rather inefficient
and contains a lot of redundancy. Moreover, it tends to select many occurrences
in different contexts: in texts like “Le 14 juillet”, “I am 17 years old”,
“latency reduction is job 1”, etc., references are parsed incorrectly. To
mitigate this problem, I considered only web pages that contained the word
bible. This improves the results and also makes the job run a lot faster (~7h
as opposed to ~30h). At this point, most of the time is spent on reading the
crawl itself and looking for bible. This first step prunes a lot, so
optimising the regular expression won’t help much in terms of performance any
more.
Results
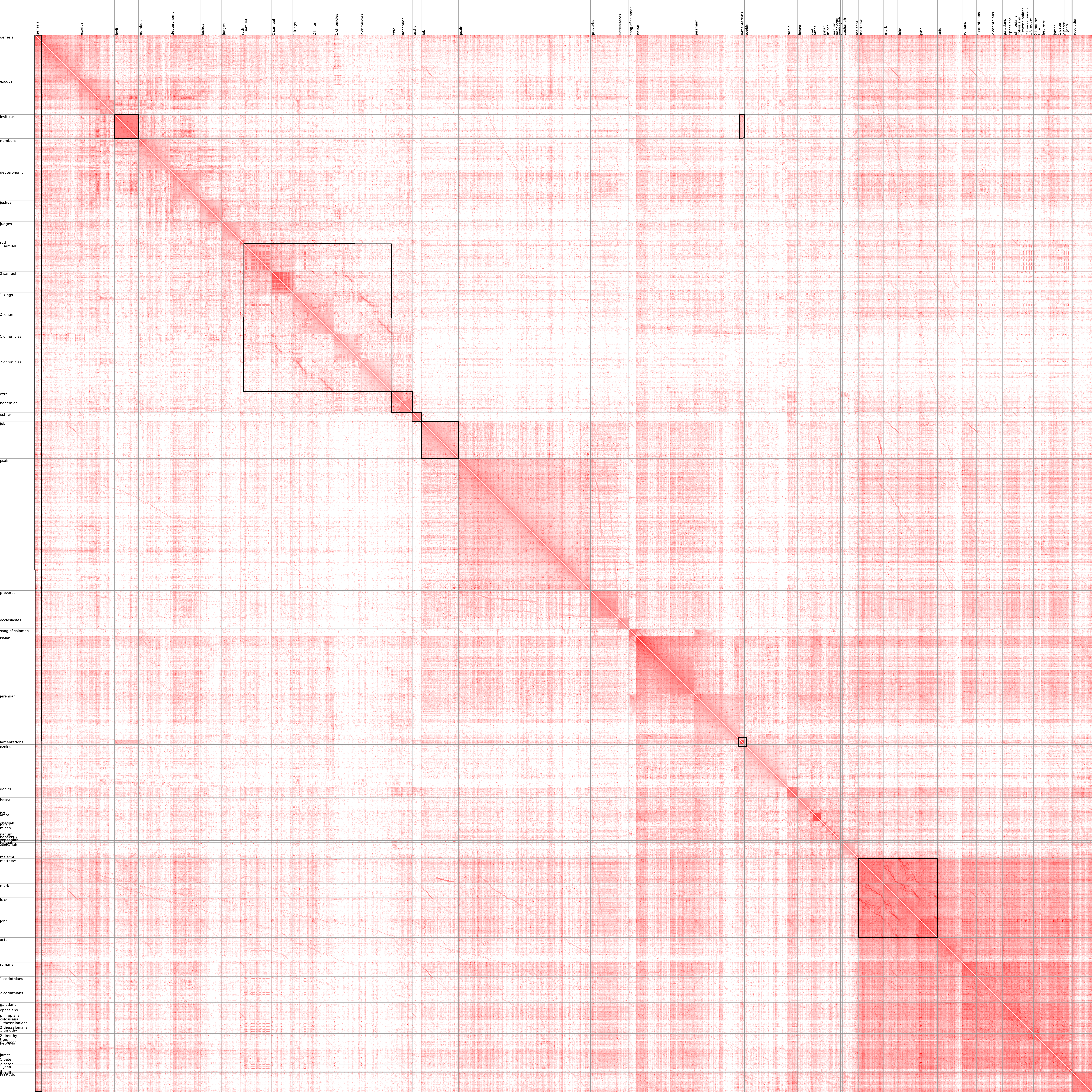
With a list of reference pairs and scores, we can make a visualisation of frequently co-mentioned passages.
Text continues below the chart.
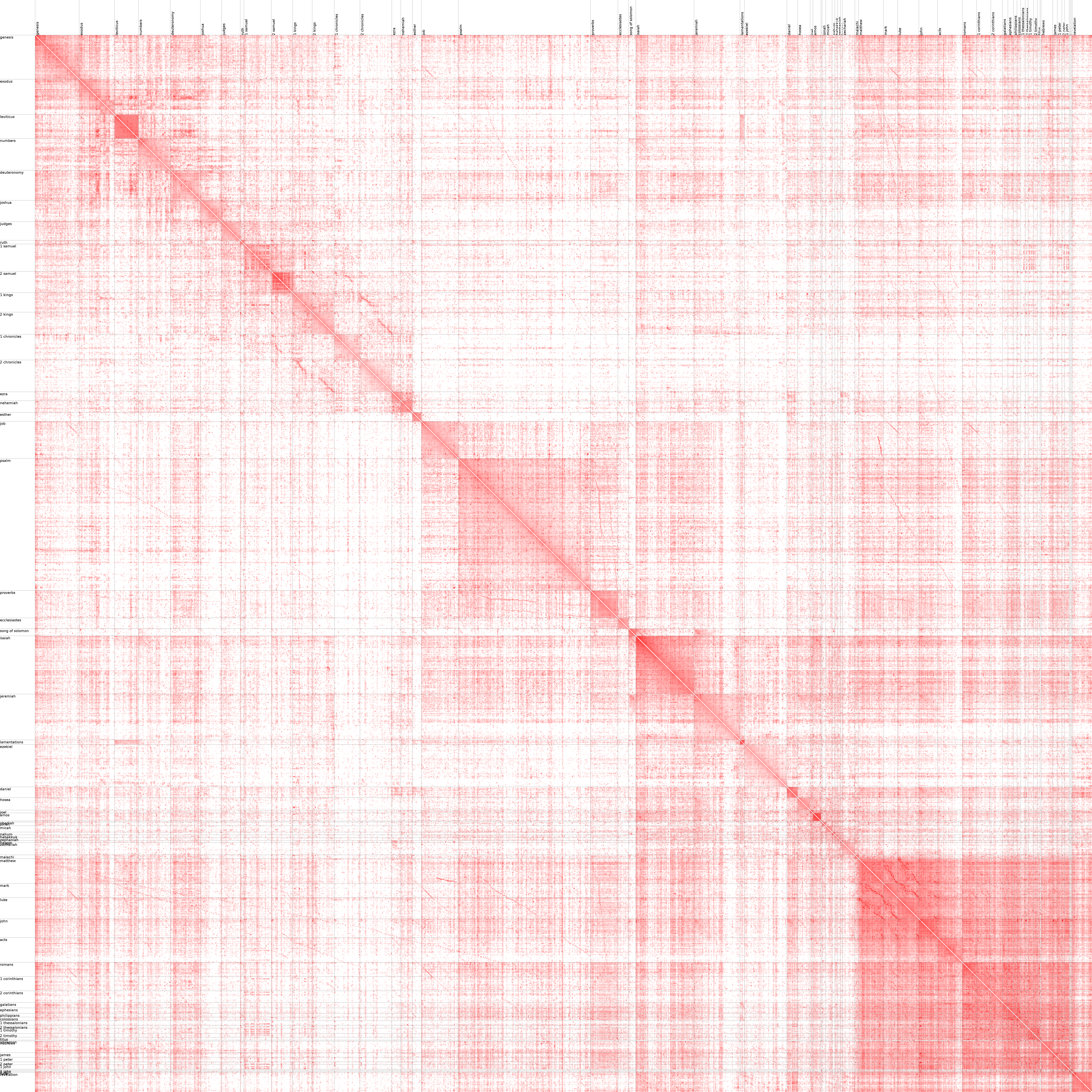
See the chart without annotations.
{kind=link}
The chart provides some useful insights:
-
The New Testament is much more popular than the Old Testament, and provides a tightly-knit faith framework. The end of Acts and the book of Revelation are clearly separated and slightly less popular. Several strong threads in the gospels show duplicate stories. These are the strongest in the three synoptic gospels (Matthew, Mark and Luke), which have the same structure.
-
The books of Ezra and Nehemia appear as closely related, which makes sense as they used to be one book.
-
The book of Esther is almost unlinked to other books. It is one of the books with the least clear theological meaning (God is not mentioned). An other less popular book is the Song of Solomon.
-
In Samuel and Kings, we see some strong threads resembling those in the gospels, again indicating duplicate stories.
-
The beginning of genesis is popular compared to any other book, which attests to both its theological importance and the common knowledge of its contents.
-
In the lower part of the chart, you can find a reading schedule which reads through the Old Testament and the New Testament simultaneously. It is not marked in the chart; finding it is left as an exercise to the reader.
-
The chart can also be used for much more detailed comparisons. We find a very bright spot between Deuteronomy 5 and Exodus 20, two versions of the ten commandments.
There are also some problems with this method:
-
As mentioned, regular expressions are not enough to parse bible references. In texts like “Le 14 juillet”, “I am 17 years old”, “latency reduction is job 1”, etc., references are parsed incorrectly (Leviticus 14, Amos 17, Job 1). A more intelligent parser that considers context should be used.
-
Finding single-chapter spots is hard because they don’t stand out much. This is a visualisation issue.
Conclusion
All in all, the chart gives a good overview of what people find important — not so much what parallels exist. So, the tool can be used for the study of reception history but less for actual exegesis.
It would be interesting to improve the parser. But also temporal analysis is a direction that can be pursued. For example using Twitter data, we may track which books are popular when. Does this change when something happens, like a terrorist attack? In this context, but also in the context of the present blog, sentiment analysis could prove an interesting new dimension.