Assignment 3, analysing vehicle information from the RDW
RDW Open Data
In this blog post we’re going to analyse a public dataset from the RDW (Rijksdienst voor het Wegverkeer), the dutch governmental body for managing (public) roads and their traffic. The RDW registers every motorized vehicle allowed to travel public roads with a licence plate, and lots of supplemental data. This dataset can be found on their website, the dataset is 6.4 GB so its quite large.
Load the spark context
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL on SQL data")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
Open the data file from the RDW
This dataset has lots of columns: 60 in total!
val rdwdata = spark.read.format("csv").option("inferSchema","true").option("dateFormat", "dd/MM/yyyy").option("header", true).load("/data/bigdata/Open_Data_RDW__Gekentekende_voertuigen.csv").cache()
rdwdata.printSchema
root
|-- Kenteken: string (nullable = true)
|-- Voertuigsoort: string (nullable = true)
|-- Merk: string (nullable = true)
|-- Handelsbenaming: string (nullable = true)
|-- Vervaldatum APK: string (nullable = true)
|-- Datum tenaamstelling: string (nullable = true)
|-- Bruto BPM: integer (nullable = true)
|-- Inrichting: string (nullable = true)
|-- Aantal zitplaatsen: integer (nullable = true)
|-- Eerste kleur: string (nullable = true)
|-- Tweede kleur: string (nullable = true)
|-- Aantal cilinders: integer (nullable = true)
|-- Cilinderinhoud: integer (nullable = true)
|-- Massa ledig voertuig: integer (nullable = true)
|-- Toegestane maximum massa voertuig: integer (nullable = true)
|-- Massa rijklaar: integer (nullable = true)
|-- Maximum massa trekken ongeremd: integer (nullable = true)
|-- Maximum trekken massa geremd: integer (nullable = true)
|-- Retrofit roetfilter: string (nullable = true)
|-- Zuinigheidslabel: string (nullable = true)
|-- Datum eerste toelating: string (nullable = true)
|-- Datum eerste afgifte Nederland: string (nullable = true)
|-- Wacht op keuren: string (nullable = true)
|-- Catalogusprijs: integer (nullable = true)
|-- WAM verzekerd: string (nullable = true)
|-- Maximale constructiesnelheid (brom/snorfiets): integer (nullable = true)
|-- Laadvermogen: integer (nullable = true)
|-- Oplegger geremd: integer (nullable = true)
|-- Aanhangwagen autonoom geremd: integer (nullable = true)
|-- Aanhangwagen middenas geremd: integer (nullable = true)
|-- Vermogen (brom/snorfiets): double (nullable = true)
|-- Aantal staanplaatsen: integer (nullable = true)
|-- Aantal deuren: integer (nullable = true)
|-- Aantal wielen: integer (nullable = true)
|-- Afstand hart koppeling tot achterzijde voertuig: integer (nullable = true)
|-- Afstand voorzijde voertuig tot hart koppeling: integer (nullable = true)
|-- Afwijkende maximum snelheid: integer (nullable = true)
|-- Lengte: integer (nullable = true)
|-- Breedte: integer (nullable = true)
|-- Europese voertuigcategorie: string (nullable = true)
|-- Europese voertuigcategorie toevoeging: string (nullable = true)
|-- Europese uitvoeringcategorie toevoeging: string (nullable = true)
|-- Plaats chassisnummer: string (nullable = true)
|-- Technische max. massa voertuig: integer (nullable = true)
|-- Type: string (nullable = true)
|-- Type gasinstallatie: string (nullable = true)
|-- Typegoedkeuringsnummer: string (nullable = true)
|-- Variant: string (nullable = true)
|-- Uitvoering: string (nullable = true)
|-- Volgnummer wijziging EU typegoedkeuring: integer (nullable = true)
|-- Vermogen massarijklaar: double (nullable = true)
|-- Wielbasis: integer (nullable = true)
|-- Export indicator: string (nullable = true)
|-- Openstaande terugroepactie indicator: string (nullable = true)
|-- Vervaldatum tachograaf: string (nullable = true)
|-- API Gekentekende_voertuigen_assen: string (nullable = true)
|-- API Gekentekende_voertuigen_brandstof: string (nullable = true)
|-- API Gekentekende_voertuigen_carrosserie: string (nullable = true)
|-- API Gekentekende_voertuigen_carrosserie_specifiek: string (nullable = true)
|-- API Gekentekende_voertuigen_voertuigklasse: string (nullable = true)
Let’s strip the data to the columns we’re going to use
val vehDF = rdwdata.select("Kenteken", "Merk", "Voertuigsoort", "Datum tenaamstelling")
Summarize the data, we see that there are some NULL variables in there
vehDF.describe().show()
+-------+--------+------------+-------------+--------------------+
|summary|Kenteken| Merk|Voertuigsoort|Datum tenaamstelling|
+-------+--------+------------+-------------+--------------------+
| count|13681070| 13681067| 13681070| 13681064|
| mean| null| null| null| null|
| stddev| null| null| null| null|
| min| 0001ES|3DOG CAMPING| Aanhangwagen| 01/01/1954|
| max| ZZ9999| wiltrailer| Personenauto| 31/12/2016|
+-------+--------+------------+-------------+--------------------+
Remove null rows, and summarize again: we see that we have removed 9 entries
val vehFilteredDF = vehDF.filter($"Kenteken".isNotNull).filter($"Merk".isNotNull).filter($"Voertuigsoort".isNotNull).filter($"Datum tenaamstelling".isNotNull)
val vehF2DF = vehFilteredDF.withColumn("Datum", vehFilteredDF("Datum tenaamstelling")).drop("Datum tenaamstelling")
vehF2DF.describe().show()
vehF2DF.printSchema()
+-------+--------+------------+-------------+----------+
|summary|Kenteken| Merk|Voertuigsoort| Datum|
+-------+--------+------------+-------------+----------+
| count|13681061| 13681061| 13681061| 13681061|
| mean| null| null| null| null|
| stddev| null| null| null| null|
| min| 0001ES|3DOG CAMPING| Aanhangwagen|01/01/1954|
| max| ZZ9999| wiltrailer| Personenauto|31/12/2016|
+-------+--------+------------+-------------+----------+
root
|-- Kenteken: string (nullable = true)
|-- Merk: string (nullable = true)
|-- Voertuigsoort: string (nullable = true)
|-- Datum: string (nullable = true)
Create a custom type to convert our SQL rows into
case class Auto(Kenteken: String, Merk: String, Voertuigsoort: String, Datum: String)
val autoDS = vehF2DF.as[Auto]
We are only interested in the year component of the date
def dateToYear (a : Auto) : Auto = {
val year = a.Datum.split("/")(2)
return Auto(a.Kenteken, a.Merk, a.Voertuigsoort, year)
}
val autoDSS = autoDS.map(dateToYear).cache()
Create a temp view of our data, this enables us to run SQL queries on this dataset
autoDSS.createOrReplaceTempView("kentekens")
Now we can finally do some real analysis on the data!
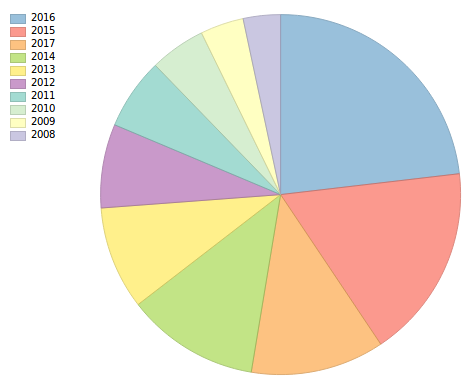
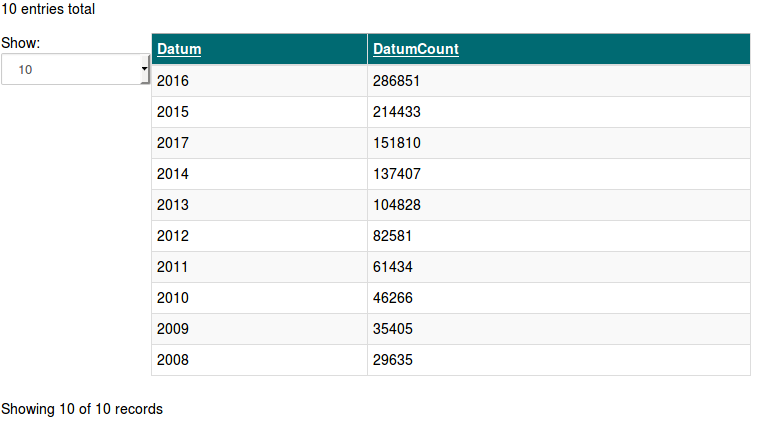
Let’s count the licence plates grouped by year
spark.sql("SELECT Datum, Count(Datum) as DatumCount FROM kentekens GROUP BY Datum ORDER BY DatumCount DESC LIMIT 10").collect()
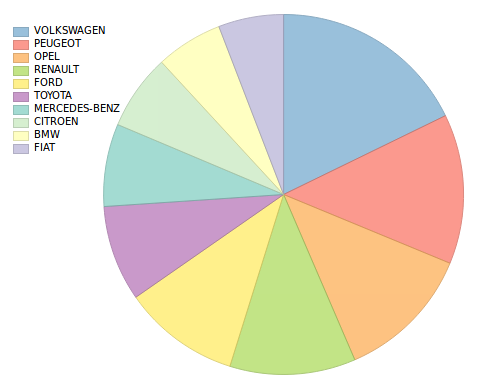
What are the top-10 popular cars in our country?
spark.sql("SELECT Merk, Count(Merk) as MerkCount FROM kentekens GROUP BY Merk ORDER BY MerkCount DESC LIMIT 10").collect()
How many Volkswagens are driving on our roads grouped by year?
spark.sql("SELECT Datum, Count(Datum) AS DatumCount FROM kentekens WHERE Merk = 'VOLKSWAGEN' GROUP BY Datum ORDER BY DatumCount DESC LIMIT 10").collect()
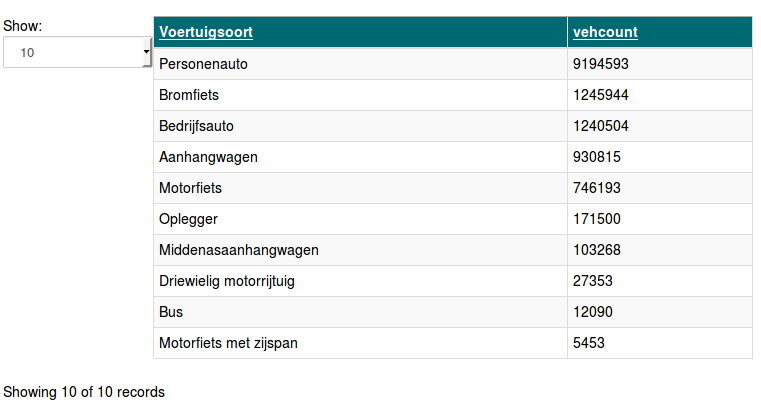
Which types of vehicles are there on our roads?
spark.sql("SELECT Voertuigsoort, Count(Voertuigsoort) as vehcount FROM kentekens GROUP BY Voertuigsoort ORDER BY vehcount DESC LIMIT 10").collect()
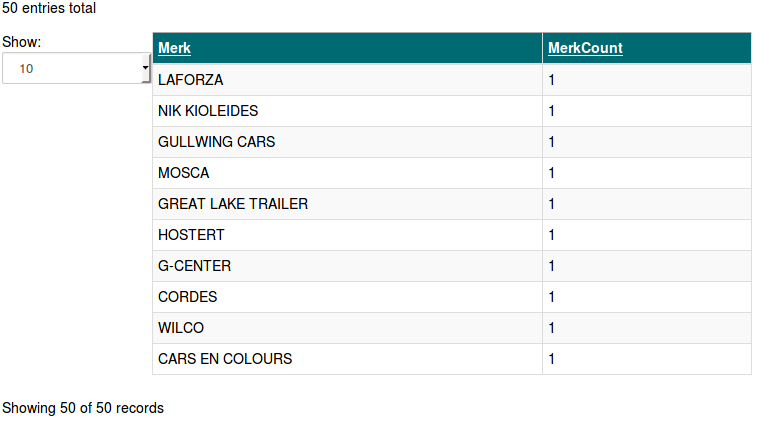
The most uncommon brands & vehicle types
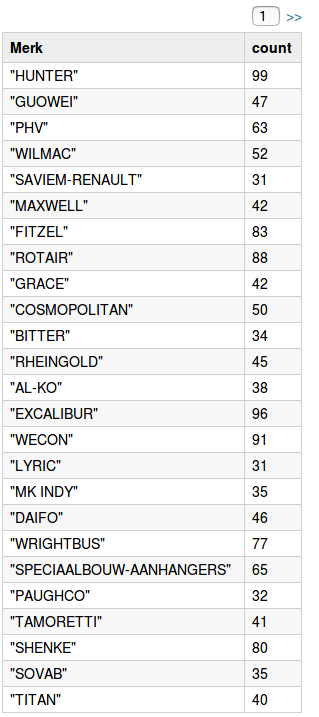
spark.sql("SELECT Merk, Count(Merk) as MerkCount FROM kentekens GROUP BY Merk ORDER BY MerkCount ASC LIMIT 50").collect()
Some rare brands (occurring between 30 and 100 times)
autoDSS.select("Merk").groupBy("Merk").count().filter($"count" >= 30 && $"count" < 100)