Assignment 4, running Scala jobs on a cluster
Introduction
Hi! In this blog post I will show how to run a Scala job in a distributed setting, we are going to analyse the COMMONCRAWL dataset of July 2016, and see how many pages each Top Level Domain (TLD) averages, after that we will analyse the site complexity (measured in amount of HTML tags), by TLD aswell. Most of the processing is performed on the SurfSara cluster. Some parts might be different when using another cluster, we’ll stick to explaining the parts that are present in this one.
Authentication
Before the cluster is available for your use you need to authenticate yourself, you can do this by installing Kerberos. Copy the surfsara specific config: surfsara.krb5.conf, and reference this file with an environment variable KRB5_CONFIG. Now you can log into the server using the command ``kinit
Utility functions
We need to create utility functions for a few things:
- Web ARChive (WARC) file content extraction
- Domain name extraction
- TLD extraction
- And lastly, a HTML Tag counter
WARC file content extraction: WARC files return Input/Output Streams instead of e.g. String objects, this is mostly because WARC files can contain non-text data (such as images), and therefore give a Stream object, where you have more control over how the bytes are processed. Since we only process text/html pages we want to read this entire stream and convert it to a String.
import java.io.InputStreamReader;
def getContent(record: WarcRecord):String = {
val cLen = record.header.contentLength.toInt
//val cStream = record.getPayload.getInputStreamComplete()
val cStream = record.getPayload.getInputStream()
val content = new java.io.ByteArrayOutputStream();
val buf = new Array[Byte](cLen)
var nRead = cStream.read(buf)
while (nRead != -1) {
content.write(buf, 0, nRead)
nRead = cStream.read(buf)
}
cStream.close()
content.toString("UTF-8");
}
Domain name extraction:
Within a website each page has a unique URL, since we want to compute statistics per domain, we need a way to extract this from the original URL. To compute this we wrap a Scala function around a java function from the default library: java.net.URI, which has an easy way to extract the host/domain from a given URI/URL.
import java.net.URI;
def getDomainName(url: String ): String = {
val uri = new URI(url);
val domain = uri.getHost()
domain.toString()
}
TLD extraction: After the domain extraction we want to get the TLD, this is easily achievable by splitting the domain on the ‘.’ character, the last element in the resulting Array is the TLD we are after.
def getTLD(url: String ): String = {
val domain = url.split("\\.").last
domain.toString()
}
HTML tag counter: A Scala wrapper function around a Java library “JSoup”, this is a tool that makes life easy when processing XML or, in our case, HTML files.
import java.io.IOException;
import org.jsoup.Jsoup;
def countTags(content: String): Int = {
try {
Jsoup.parse(content).getAllElements().size()
}
catch {
case e: Exception => throw new IOException("Caught exception processing input row ", e)
}
}
As you can see, each of these functions are wrapped in Scala functions, this is due to the neccesity of serializing each function for transport to the executor nodes. Although you might be tempted to implement these functions as lambas/anonymous functions, this usually leads to some nasty errors when Spark tries to serialize these (although it is possible, when giving the compiler strong hints how to compile these classes using libraries like KryoSerializer).
Scala code
Now that we have defined our helper functions we can move on to the good stuff: our Spark code!
First we want to define one or more WARC files for read into RDDs.
val warcfile = "/data/bigdata/course2.warc.gz"
//val warcfile = "/data/public/common-crawl/crawl-data/CC-MAIN-2016-07/segments/*/warc/*.warc.gz"
val warcf = sc.newAPIHadoopFile(
warcfile,
classOf[WarcInputFormat], // InputFormat
classOf[LongWritable], // Key
classOf[WarcRecord] // Value
)
We can transform these in a few steps into our desired state. Since we have two goals with our dataset we will split our code here into two different subsections:
- Average pages per site per TLD
- Average complexity (HTML tags) per site per TLD
Average pages per site per TLD
Count # pages per site
We only search for ‘response’ type files (HTTP requests are stored aswell usually), we only want http or https pages, not any wierd URIs to ftp or the like. After that we filter down to text/html pages to remove images or plain text files that are also caught in the crawl. Now we can map each page to Key/Value (K/V) with as key the domain, and value ‘1’ (the page count). These are subsequently summed in the reduceByKey command.
val sites = warcf.
filter{ _._2.header.warcTypeIdx == 2 /* response */ }.
filter{ _._2.header.warcTargetUriStr.startsWith("http") }.
filter{ _._2.getHttpHeader().contentType != null}.
filter{ _._2.getHttpHeader().contentType.startsWith("text/html") }.
map{wr => (getDomainName(wr._2.header.warcTargetUriStr), 1)}
.reduceByKey( _ + _ ).cache()
Average # of pages per TLD We want to average per site, per TLD, in order to do that we need to keep track of the total amount of sites we encountered for each TLD, and also for their respective amount of pages. Therefore we map each domain to K/V with as key the TLD, and value a pair of (nr_pages, nr_sites). This is subsequently mapped to an average by dividing the former by the latter.
val tlds = sites.
map{site => (getTLD(site._1), (site._2, 1))}.
reduceByKey((a,b) => (a._1 + b._1, a._2 + b._2)).
mapValues(a => (a._1.toFloat / a._2)).cache()
Average complexity (HTML tags) per site per TLD
We use the same strategy as with the page count, now replacing the ‘1’ with the number of HTML tags.
val tags = warcf.
filter{ _._2.header.warcTypeIdx == 2 /* response */ }.
filter{ _._2.header.warcTargetUriStr.startsWith("http") }.
filter{ _._2.getHttpHeader().contentType != null}.
filter{ _._2.getHttpHeader().contentType.startsWith("text/html") }.
map{wr => ( getDomainName(wr._2.header.warcTargetUriStr), countTags(getContent(wr._2)) )}.cache()
The subsequent map/reduce is the same as in the previous example:
val tags2 = tags.
map{site => (getTLD(site._1), (site._2, 1))}.
reduceByKey((a,b) => (a._1 + b._1, a._2 + b._2)).
mapValues(a => (a._1.toFloat / a._2)).cache()
Finally
After we have these values we can write these to a file on the HDFS file system:
The coalesce moves the data from the separate executors to only one, which reduces the amount of files written by saveAsTextFile to only one file, instead of nr_of_executor files.
tlds.coalesce(1).saveAsTextFile("avg_pages")
tags2.coalesce(1).saveAsTextFile("avg_tags")
Some results:
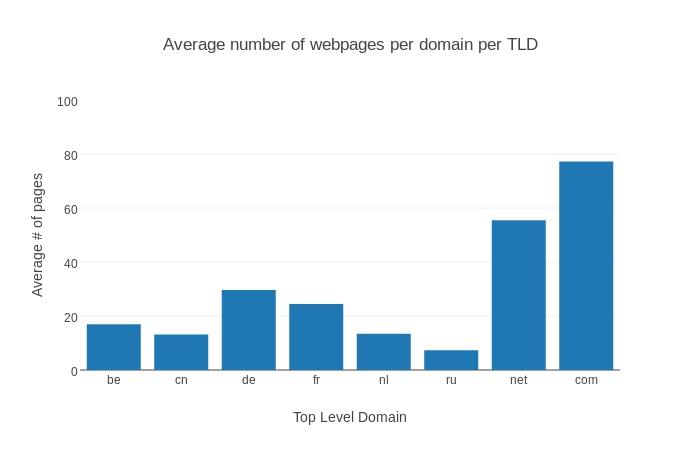
Since we currently have around 1500 TLDs, visualizing them all becomes a bit tricky, especially with some extreme outliers. Thus we will only focus on a select few TLDs which are quite frequent and relate closely to my “native” TLD: .nl. The complete graph is here, warning: large image.
{kind=link}
The TLDs we will use:
.com
.net
.info
.nl
.uk
.de
.be
.ru
.cn
This does give us a nice graph, where notably the domains of .net and .com have the highest average, my guess is that this is due to the fact that mostly larger (international) companies use these domains, instead of a local domain. Russia has the lowest amount of pages per site, although I have no clue why, maybe internet usage is pretty low in comparison to the other countries?
Unfortunately the tag counter crashed halfway through the process due to an unspecified error, which made debugging pretty hard.