Sparkling Spark Hands-on session with Spark RDDs
In Assignment 3 you meet Spark and gain in-depth knowledge of the Resilient Distributed Dataset (RDD).
The first learning objective is to acquire the competences to carry out basic data tasks with Spark, and contrast the user experience to that of using the Map Reduce framework. A secondary objective is to learn to work with Zeppelin Notebooks, that will save you time later on in the course. The third objective is to improve your understanding of the Spark execution model, by looking into detail into Spark jobs, tasks, partitioning and more.
Accept the assignment via Github for Education, using this invitation link
Clone the assignment repository, where you find two Zeppelin notebooks, A3a (basic Zeppelin usage and an introduction to Spark RDDs) and A3b (in-depth understanding of RDDs and their partitioning). The split between parts A and B corresponds rougly to what we’d figure you can during the week, assuming you spread these A3 lab session activities over a two week period.
Create the course container for assignment 3 with the following docker command:
docker create --name hey-spark -it -p 8080:8080 -p 9001:9001 -p 4040:4040 rubigdata/course:a3
Ports 8080 and 4040 are used by Spark, we configured Zeppelin to appear on port 9001.
Start the container:
docker start hey-spark
Connect to the Zeppelin UI from your browser; giving it a little time to start all the services inside the container.
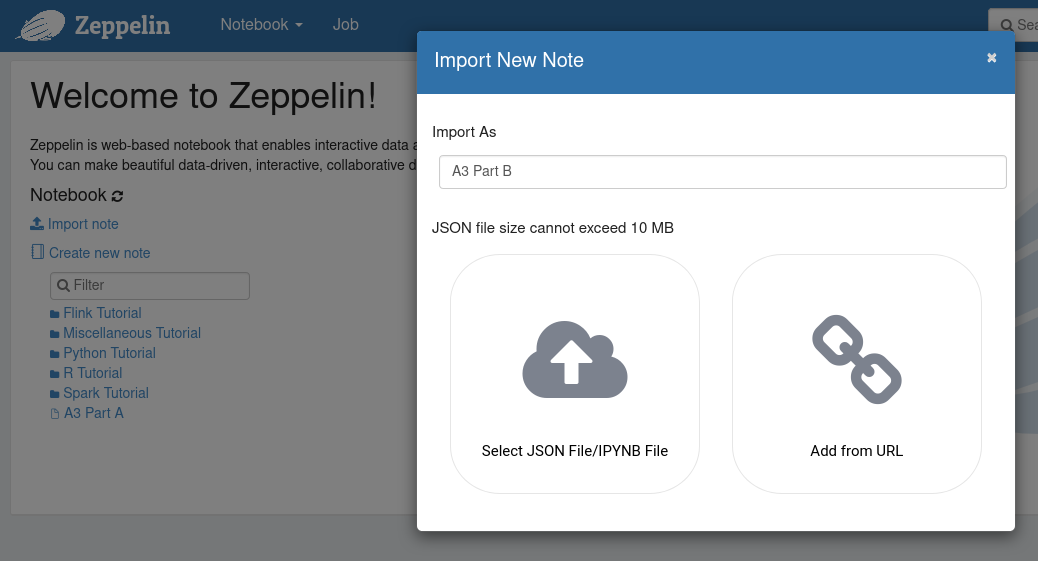
Import the notebooks from your assignment repository, and start exploring
Spark using the RDD API. You find a screenshot for importing a notebook
below; type the desired name, click on Select JSON File, and select
the corresponding .zpln file from your cloned assignment repository
(using the file browser).
Warning: the course notebook that you adapt or any new one you
create, only exist inside the hey-spark docker container. Make a
backup on your host on a regular basis; click the Export this note
(zpln) icon in the menu bar to download a copy to the Downloads
folder of your Web browser.

Oh, and do not export it as an IPython notebook, because a subsequent
import messes up every single cell with %spark code by prepending
%python (been there, done that).
Blog Post
The assignment is to write a blog post about your experience with Spark.
The provided notebooks try to make you think - some of the commands are cryptic, urging you to refer to the slides on RDDs, data representation and query processing internals of the Spark framework.
For your blogpost, discuss your understanding of the Spark internals, after having gone through the notebooks. Ideally, you adapt the examples in the notebook to a more interesting example, inspired from a real need or usage scenario, so your blog post presents an interesting story to the reader.
Interesting aspects of Spark you might want to address include its lazy evaluation, the effect of caching RDDs, partitioning of the RDDs, etc. Ideally, you would experiment with a few alternative solutions for the same high-level objective, and/or different choices in the setup of the dataset (like number of partitions, how to avoid shuffles, relationship between number of shuffles and overall processing cost, etc.). How does the query optimizer help reduce processing costs, and where does it need help?
Done
When you complete the assignment, push your blog post to the first
assignment’s repository. Include a link to the published blog post in
the README.md in the third assignment repository. Push the updated
README as well as your own code or notebooks to the third assignment
repository.
Back to assignment overview.